

Os portais públicos implementam diversas barreiras – como CAPTCHAs, bloqueios de IP e autenticação reforçada – para proteger dados e impedir acessos automatizados indesejados. Esses mecanismos não diferenciam entre robôs maliciosos, que visam práticas ilegais ou abusivas, e robôs legítimos, que realizam apenas a extração autorizada de informações públicas ou consentidas. Como resultado, mesmo ferramentas de automação éticas enfrentam os mesmos obstáculos e precisam de estratégias para contorná-los de forma responsável.
Por trás da automação, está o conceito de ETL (Extract, Transform, Load) – um processo estruturado que envolve extrair informações de portais, transformá-las em dados organizados e carregá-las para uso analítico. Para isso, é necessário desenvolver ou programar robôs capazes de acessar sites, preencher formulários, navegar entre páginas e estruturar resultados em formatos utilizáveis. No entanto, é nesse processo que os problemas surgem, como mudanças em códigos de páginas, CAPTCHAs e até a necessidade de autenticação.
Como desenvolver automações eficazes, evitando que sejam confundidas com acessos indevidos? Neste artigo, exploramos cinco desafios comuns da automação em portais públicos e apresentamos soluções práticas para superá-los. Continue a leitura e descubra como transformar obstáculos em oportunidades!
O primeiro grande desafio na automação da coleta de dados em portais públicos é lidar com as diferenças estruturais das páginas. Isso ocorre porque cada site possui um código HTML único, que precisa ser analisado detalhadamente para que os dados possam ser extraídos de maneira eficaz.
Alguns sites apresentam códigos bem estruturados, com dados organizados e identificáveis por classes ou tags específicas. Nessas situações, a tarefa de desenvolver um robô para raspagem de dados é mais simples e rápida. No entanto, portais com códigos desorganizados ou pouco padronizados exigem um esforço adicional para localizar as informações relevantes.
Além disso, há diferenças significativas na forma de entrega dos dados. Alguns portais fornecem informações diretamente em tabelas visíveis no HTML, enquanto outros utilizam formatos mais complexos, como JavaScript para carregamento dinâmico ou APIs internas, o que demanda a utilização de ferramentas específicas, como Selenium ou bibliotecas avançadas como Scrapy e BeautifulSoup.
Mesmo após uma implementação bem-sucedida da automação, mudanças nos sites podem interromper o funcionamento dos robôs. Isso acontece porque pequenas atualizações no código HTML ou no layout da página podem:
Por exemplo, portais governamentais, como os de transparência, frequentemente sofrem atualizações de layout para atender às normas de acessibilidade ou para modernização da interface, o que pode interromper a automação temporariamente.
Na automação da coleta de dados em portais públicos, o bloqueio de IP é uma das principais barreiras enfrentadas. Os bloqueios de IP são barreiras comuns aplicadas indiscriminadamente a todos os tipos de acessos automatizados. Isso inclui tanto robôs maliciosos, que buscam explorar falhas ou extrair dados ilegalmente, quanto robôs legítimos, que se limitam a informações públicas e consentidas. Para contornar essa limitação, utilizamos proxies rotativos e outras técnicas, garantindo que exista um acesso estável aos dados a que têm direito. É nesse cenário que os servidores proxy se tornam uma solução indispensável.
Um servidor proxy atua como intermediário entre o seu dispositivo e o site que você deseja acessar. Em vez de acessar o portal diretamente com o seu IP real, o proxy faz a requisição usando um IP alternativo, mascarando sua identidade e evitando o bloqueio. Esse processo oferece duas vantagens essenciais:
Exemplo Prático:
Para acessar dados fiscais distribuídos em portais estaduais (como as Secretarias da Fazenda), proxies garantem acesso estável, permitindo a coleta simultânea de diferentes regiões.
Os proxies rotativos são amplamente utilizados em projetos de raspagem de dados, especialmente em portais públicos com proteções mais severas. Eles funcionam da seguinte maneira:
Imagine que você precisa coletar dados de 10 mil processos judiciais em um site de tribunais. Usando um único IP, após algumas centenas de acessos, seu endereço seria bloqueado. Com proxies rotativos, cada requisição vem de um IP diferente, permitindo coletas simultâneas e em grande escala sem interrupções.
Existem dois tipos principais de proxies: gratuitos e pagos. A escolha depende do volume de dados a ser coletado, dos recursos disponíveis e do nível de confiabilidade desejado.
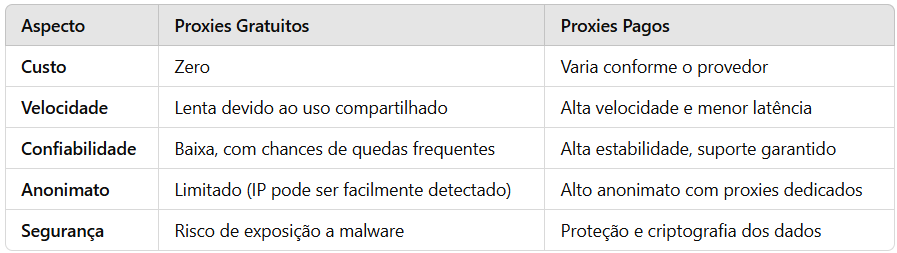
Os proxies pagos oferecem vantagens significativas, como estabilidade, velocidade e anonimato, fatores essenciais para a automação de grandes volumes de dados. Além disso, fornecedores profissionais geralmente disponibilizam proxies rotativos, possibilitando uma operação contínua e eficiente.
3. Captcha
Captcha é o acrônimo em inglês para “Completely Automated Public Turing test to tell Computers and Humans Apart”, ou – no bom português – Teste Turing público completamente automatizado para diferenciar computadores e humanos.
Assim como sugere o nome, tem o objetivo de identificar se a ação em um site está sendo realizada por uma pessoa ou um robô. Caso seja um robô, o acesso pode ser bloqueado. O uso de captcha é cada vez mais comum em sites para impedir atividades suspeitas e ameaças.
Porém, quando precisamos usar um robô para automatizar tarefas repetitivas, que seriam feitas manualmente, e facilitar o dia a dia da empresa, o captcha é um problema que precisa ser contornado.
Para isso, temos três opções:
Portais públicos frequentemente utilizam CAPTCHAs para proteger dados sensíveis ou evitar atividades automatizadas excessivas. Alguns cenários comuns incluem:
Em muitos casos, o acesso a determinadas informações públicas ou a dados cujo proprietário forneceu autorização requer etapas adicionais de autenticação, como login, uso de certificados digitais ou tokens temporários. Embora esses procedimentos busquem controlar o uso indevido de dados, eles não fazem distinção entre acessos legítimos e maliciosos.
As soluções precisam reproduzir fielmente o fluxo de autenticação, garantindo que apenas dados permitidos sejam coletados, mantendo total conformidade com as normas e protegendo o ambiente contra abusos.
Mesmo após superar desafios como bloqueios de IP, CAPTCHAs e autenticação, podem ocorrer falhas durante o acesso ao site. Isso acontece quando:
Essas situações são comuns ao lidar com portais públicos, especialmente os que têm um grande volume de acessos ou infraestrutura limitada. Portanto, é essencial prever retentativas automáticas no código, permitindo que o robô tente novamente antes de desistir.
Além de definir o número de tentativas e os intervalos, é importante prever situações específicas no código, garantindo que a automação saiba como agir em diferentes cenários:
A automação da coleta de dados em portais públicos apresenta desafios complexos: desde a diversidade estrutural dos sites até bloqueios de IP, CAPTCHAs e sistemas de autenticação restritos. Implementar soluções personalizadas para contornar esses obstáculos exige tempo, recursos financeiros e conhecimento técnico, além de um esforço contínuo de monitoramento e manutenção.
Com o Plexi, você não precisa se preocupar com nenhum desses desafios. Nossa solução automatiza a consulta de dados e certidões em mais de 100 portais públicos em segundos, permitindo que sua empresa acesse informações de forma rápida, precisa e sem interrupções.
Por que escolher o Plexi?
Tudo isso é oferecido por meio de um portal intuitivo ou integração via API, com um tempo médio de obtenção das informações em apenas 20 segundos.
O Plexi é uma ferramenta SaaS que pode ser acessada de forma online em qualquer lugar, com implementação facilitada, eliminando a necessidade de instalação local e complicações de aplicações que rodam em máquina.
Fale agora com nossos especialistas e descubra como o Plexi pode simplificar sua rotina na Gestão de Riscos e impulsionar seus resultados.
1. Quais são os principais desafios na automação da coleta de dados em portais públicos?
Os principais desafios incluem:
As proteções adotadas pelos portais públicos visam coibir atividades maliciosas, mas acabam impactando também as iniciativas legítimas que coletam dados públicos ou autorizados.
2. Como o Plexi resolve os problemas de bloqueio de IP e CAPTCHAs?
O Plexi utiliza tecnologias avançadas que automatizam o processo de coleta sem a necessidade de proxies ou resolução manual de CAPTCHAs. Sua infraestrutura já contempla soluções robustas que garantem o acesso contínuo aos portais, mesmo em cenários com bloqueios ou mecanismos de proteção avançados.
3. Por que as mudanças frequentes nos sites impactam a automação?
Pequenas alterações no código HTML, layout ou políticas de segurança de um site podem quebrar os scripts de automação existentes. Isso exige um monitoramento contínuo e ajustes rápidos no código para que o processo de coleta continue funcionando corretamente.
4. Quais são os benefícios de usar o Plexi ao invés de desenvolver uma solução interna?
O Plexi oferece: